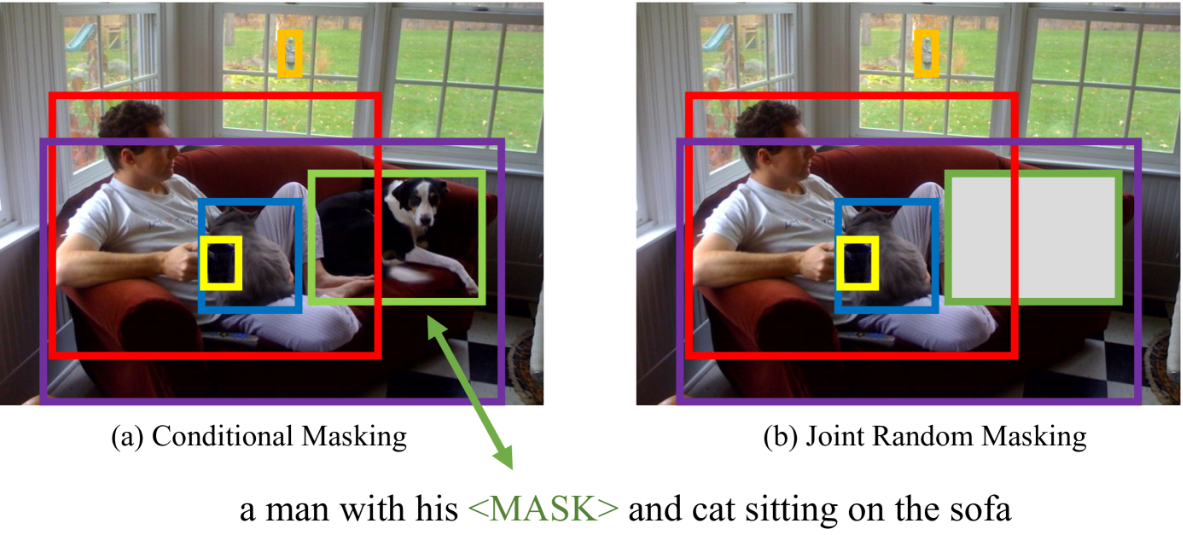
UNITER: UNiversal Image-TExt Representation Learning 0.초록 image-text 공동 임베딩은 대부분의 Vision-and-Language(V+L)태스크의 기반이다. 이때 멀티모달 인풋들은 시각적 그리고 언어적 이해를 위해 동시에 처리된다. 해당 논문에서 저자는 UNITER를 소개한다. 데이터셋(COCO, Visual Genome, Conceptual Captions, and SBU Captions) UNITER는 다양한(이질적인) 다운스트림 V+L 태스크를 가능하게 한다. 저자는 네 가지 사전 훈련 태스크를 고안했다 Masked Language Modeling(MLM) Masked Region Modeling (MRM, with three variants) I..