UNITER: UNiversal Image-TExt Representation Learning
0.초록
image-text 공동 임베딩은 대부분의 Vision-and-Language(V+L)태스크의 기반이다.
이때 멀티모달 인풋들은 시각적 그리고 언어적 이해를 위해 동시에 처리된다.
해당 논문에서 저자는 UNITER를 소개한다.
데이터셋(COCO, Visual Genome, Conceptual Captions, and SBU Captions)
UNITER는 다양한(이질적인) 다운스트림 V+L 태스크를 가능하게 한다.
저자는 네 가지 사전 훈련 태스크를 고안했다
- Masked Language Modeling(MLM)
- Masked Region Modeling (MRM, with three variants)
- Image-Text Matching(ITM)
- Word-Region Alignment(WRA)
이전 논문과 다른 점은 두 모달에 랜덤 마스킹을 동시에 적용한다는 점이다.
저자는 사전 학습 과제에서 조건부 마스킹을 사용한다.(즉 masked language/region modeling은 image/text의 전체 데이터에 조건이 지정된.)
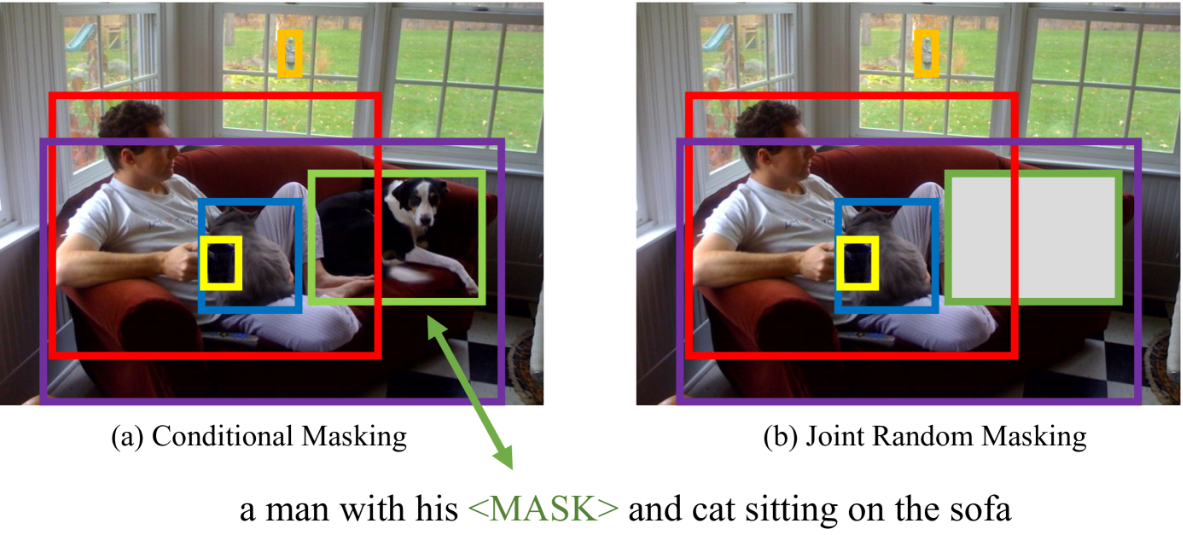
global image-text alignment를 위해 ITM에 추가로 사전 훈련 동안 단어와 이미지 region 사이의 정확한 alignment를 명시적으로 돕기 위해 Optimal Transport(OT)의 사용을 통한 WRA를 제안한다.
전체적인 분석에서 양 방향 마스킹과 OT 기반의 WRA가 더 좋은 사전 훈련에 기여했음을 알 수 있다.
저자는 또한 ablation study를 통해 사전 훈련의 최적 조합을 찾았다.
추가적인 실험에서 UNITER이 6개의 태스크에 대해 SOTA 수준을 넘어섰다.
(VQA, Image-Text Retrieval, Referring Expression Comprehension, Visual Commonsense Reasoning, Visual Entailment, and NLVR)
1.소개
대부분의 V+L 태스크들은 이미지와 텍스트 내에서 시각과 텍스트의 단서 사이의 의미적 차이를 잇기 위해 동시 멀티모달 임베딩에 의존했다.
(심지어 얘들은 특정 태스크에서만 사용 가능한 표현이었음)
과거에 논문들은 각 분야에서 SOTA를 달성했지만 각 구조가 다양하고 표현이 매우 태스크 한정적이어서 다양한 태스크에 대해 일반화할 수 없었다.
이런 점에서 모든 V+L 태스크에서 보편적인 image-text 표현들을 학습할 수 있을까?라는 질문이 생겼다.
이 관점에서 저자는 UNITER(UNiversal Image-TExt Representation(UNITER)을 도입한다.
이는 동시 멀티 모달 임베딩을 위한 거대한 사전 학습 모델이다.
저자는 모델의 코어로 트랜스포머를 선택했고 이는 문맥적인 표현을 학습하기 위해 고안된 self-attention 매커니즘을 활용한다.
BERT에서 영감을 받아 저자는 4가지 사전 학습 태스크를 통해 UNITER을 사전 훈련시켰다.
- MLM: conditioned on image
- MRM conditioned on text
- ITM
- WRA
MRM의 효과성을 추가로 조사하기 위해, 저자는 3개의 MRM 변수들을 제안한다.
(1) Masked Region Classification(MRC)
(2) Masked Region Feature Regression(MRFR)
(3) Masked Region Classification with KL-divergence(MRC-kl)
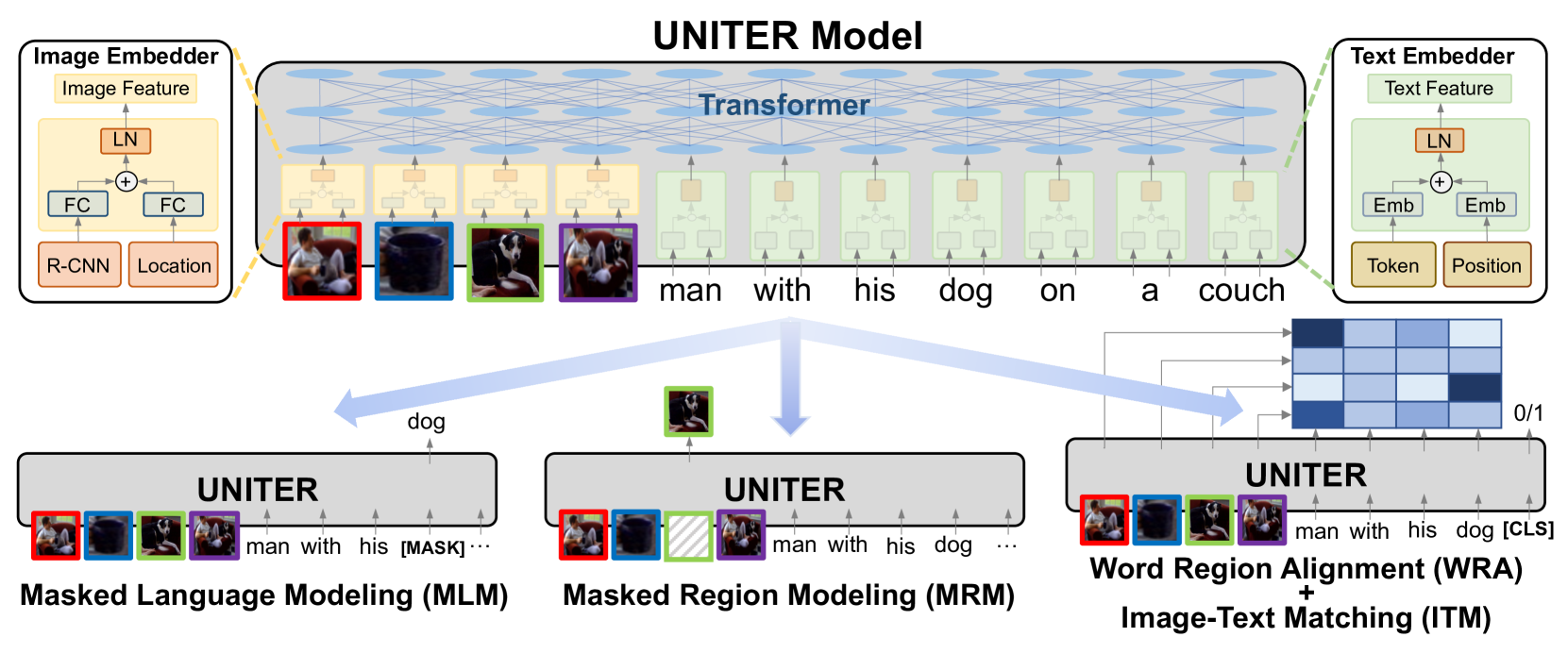
위 그림에서 UNITER는 우선 image regions와 textual words(tokens and positions)를 이미지 임베더와 텍스트 임베더를 통해 일반적인 임베딩 공간으로 인코딩한다.
그 후 트랜스포머 모듈이 잘 고안된 사전 훈련 태스크를 통해 각 region과 각 단어에 대해 일반화 가능한 문맥화된 임베딩을 학습한다.
이전 멀티모달 사전 훈련과 비교할 때
(1) 저자의 masked language/region modeling은 두 모달리티에 동시 무작위 마스킹을 적용하기보다 image/text의 전체 관측으로 조건이 지정된다.
(2) 저자는 OT의 사용을 통해 단어와 이미지 지역 사이의 alignment를 위해 WRA 사전 훈련 태스크를 도입했다.
직관적으로 , OT 기반의 학습은 한 분포에서 다른 분포로의 전환 비용 최소화를 통해 분포 매칭에 대해 최적화를 목표로 한다.
저자의 맥락에서는 image regions부터 문장 내의 words까지의(반대로 words부터 region까지도) 임베딩 전환 비용을 최소화하는 것이다.
그러므로 더 좋은 cross-modal alignement를 향해 최적화하는 것이다.
저자는 조건부 마스킹과 OT 기반 WRA 모두가 성공적으로 misalignment 오류를 완화하는 것을 보여줄 것이다.(images와 text 사이의)
그리고 이는 다운스트림 태스크에 대해 더 좋은 동시 임베딩을 제공할 것이다.
UNITER의 힘을 보여주기 위해 저자는 9개 dataset에 대해 6개의 V+L 태스크를 평가했다.
저자의 contribution은 (1) UNITER를 도입했고 (2) 마스크된 language/region 모델링에 대해 조건부 마스킹을 보였고 사전 학습을 위해 OT 기반의 Word-region Alignment 태스크를 제안했고 (3) V+L의 벤치마크에서 SOTA성능을 보였다.
저자는 추가적인 실험에서 멀티모달 인코더 학습을 위해 각 사전 학습 태스크/데이터셋의 효율성에 대해 유용한 인사이트를 제공한다.
2. Related Work
자기 지도 학습은 지도학습의 원본 데이터를 사용하며 이는 많은 CV 태스크에 사용된다.
최근에 사전 학습된 언어 모델은 NLP 태스크에서 많은 발전을 이뤘다.
여기에는 두 가지 핵심이 있는데: 언어 corpus에서 효과적인 사전 훈련 태스크 그리고 맥락적인 텍스트 표현을 위한 트랜스포머의 사용이다.
더 최근에는 멀티 모달 태스크에 대해 자기-지도학습에 대한 관심이 커지고 있다.(거대한 데이터셋-image/video와 텍스트 쌍에 대한 사전훈련)
예를 들어 ViLBERT와 LXMERT는 이미지와 텍스트 각각에 대한 두 트랜스포머가 세 번째 트랜스포머에서 융합되는 적용하여 구조를 제안했다.
3.UNiversal Image-TExt Representation
이 파트에서 저자는 UNITER의 모델 구조를 소개하고 V+L 데이터 셋에 대한 사전 훈련 태스크를 설명한다.
3.1 Model Overview
위 이미지에서도 나와있듯이 image와 문장의 쌍에 대해서 UNITER가 이미지의 시각적 지역과 문장의 토큰을 인풋으로 받는다.
각 이미지 임베더와 텍스트 임베더가 각각의 임베딩을 추출한다.
이러한 임베딩들은 트랜스포머로 들어가서 양 모달에 대한 문맥화된 임베딩을 학습한다.
주목할 점은 트랜스포머에서 self-attention 매커니즘은 순서와 상관이 없다.
그러므로 명시적으로 토큰의 포지션과 이미지 지역의 주소를 추가적인 입력으로 인코딩해야 한다.
특히, 이미지 임베더에서 저자는 처음에 Faster R-CNN을 사용하여 각 지역에 대해 시각적 특징(pooled ROI features)들을 추출했다.
이어서 저자는 7차원 벡터를 통해 각 지역의 장소 특징을 인코딩했다.
시각적 그리고 주소적 특징들 모두 FC layer에 들어가서 같은 임베딩 공간으로 사영된다.
각 지역에 대한 마지막 시가적 임베딩은 두 FC 출력물을 합치고 layer normalization 층으로 넘기는 것으로 끝이난다.
텍스트 임베더에서 BERT를 따라 단어조각으로 문장을 토큰화한다.
각 sub-word 토큰에대한 마지막 표현은 word embedding과 position embedding을 합치고 LN(layer normalize) 층을 통과하여 끝이난다.
저자는 사전 훈련을 위한 4가지 태스크를 도입했는데
(Masked Language Modeling-MLM,
Masked Region Modeling-MRM,
Image-Text Matching,
Word-Region Alignment)
그림에서 볼 수 있듯이 인풋으로부터 랜덤하게 어떤 단어와 지역을 마스크하고 출력으로 가려진 단어와 지역을 복구하는 것을 학습하는 MRM와 MLM은 BERT와 유사하다.
특히 단어 마스킹은 [MASK] 토큰으로 대체되고 region masking은 모든 시각적 특징이 0으로 마스킹된다.
주목할 점은 다른 모달이 손상되지 않으면서 한 모달에 마스크를 씌우는 것이다.
이는 마스크 지역이 마스크 단어에 의해 표현될 때 잠재적인 misalingment 오류를 예방한다.
저자는 또한 ITM을 통해 전체 이미지와 문장 사이의 instance-level alignment를 학습했다.
훈련 동안 긍정과 부정 분장 쌍을 샘플링하고 그들의 매칭 점수를 학습했다.
추가로 토큰과 이미지 지역 사이의 더 좋은 alignment를 제공하기 위해 OT의 사용을 통한 WRA를 제안했는데 이는 효과적으로 문맥이 반영된 이미지 임베딩을 단어 임베딩으로(반대도) 전송하는 최소화 비용을 계산한다.
추론된 전송 계획은 더 좋은 모델 alignment를 위한 도구이다.
실험적으로 저자는 조건부 마스킹과 WRA가 성능 향상에 어떤 영향을 미치는지 보였다.(4.2에서 계속)
UNITER이 이런 태스크를 사전 학습하기 위해 저자는 각 미니 배치에 하나의 태스크를 랜덤하게 샘플하고 각 SGD 업데이트에 대해 하나의 목적함수에 대해서 훈련했다.
3.2 Pre-training Tasks
Masked Language Modeling(MLM)
$v=\{v_1,...,v_k\}$를 image regions라고 하고
$w=\{w_1,...,w_k\}$를 입력 단어들이라고 하고
$m \in N^m$을 마스크 인덱스라고 할 때
MLM에서 저자가 랜덤하게 인풋단어를 마스크하는 확률은 15%이고 마스킹하게 되면 $w_m$은 [MASK] 토큰으로 교체된다.
목표는 주위 단어${w}_{\setminus\mathbf{m}}$ 와 모든 image region v를 기반으로 부정적인 로그 우도함수를 최소화함으로써 마스킹된 단어를 예측하는 것이다.
$\mathcal{L}_{\text{MLM}}(\theta)=-\mathbb{E}_{(\mathbf{w},\mathbf{v})\sim D}\log P_{\theta}(\mathbf{w}_{\mathbf{m}}|\mathbf{w}_{\setminus\mathbf{m}},\mathbf{v})\,,$
이때$\theta$는 훈련가능한 파라미터이고 각 쌍 (w,v)는 훈련셋 D에서 샘플링되었다.
Image-Text Matching(ITM)
ITM에서는 추가적인 토큰 [CLS]가 모델에 들어가는데 이는 두 모달의 혼합된 표현을 가르킨다.
ITM의 인풋은 문장과 일련의 이미지 지역들이고 아웃풋은 이진 라벨(0,1)인데 이는 샘플링된 쌍이 매치되는지를 가르킨다.
저자는 입력 이미지-텍스트 쌍의 동시 표현으로서 [CLS] 토큰의 표현을 추출한다.
그리고 이를 FC와 sigmoid 함수를 통해 0과 1 사이로 예측한다.
아웃풋 스코어는$s_\theta(w,v)$로 표현한다.
ITM 지도학습은 [CLS] 토큰에 대한 것이다.
훈련 동안 각 스텝마다 데이터셋 D에서 저자는 긍정 또는 부정쌍의 (w,v)를 샘플링한다.
부정 쌍은 긍정 쌍의 이미지 혹은 텍스트를 다른 샘플에서 랜덤하게 선택함으로써 생성된다.
저자는 이 태스크에서 binary cross-entropy 손실 함수를 선택했다.
$$\mathcal{L}_{\text{ITM}}(\theta)=-\mathbb{E}_{(\mathbf{w},\mathbf{v})\sim D}[y\log s_{\theta}(\mathbf{w},\mathbf{v})+(1-y)\log(1-s_{\theta}(\mathbf{w},\mathbf{v}))])\,.$$
Word-Region Alignment(WRA)
저자는 WRA를 위해 OT를 사용하는데 이는 w와 v 사이의 alignment를 최대화하기 위해 전송 계획$T \in R^{T*K}$이 학습된다.
OT는 WRA에 대해 좋은 선택을 만드는 몇가지 특이한 특징들을 처리한다.
- Self-normalization: 모든 T의 요소들의 합은 1이다.
- Sparsity: 정확하게 해결될 때, OT는 (2r-1) non-zero 요소들을 포함하는 sparse solution T를 산출한다.(이때 r=max(K,T))→이는 결과적으로 더 해석가능하고 강건한 alignment를 제공한다.
- Efficiency: 전통적인 선형 프로그래밍 해결자들과 달리 오직 matrix-vector 곱만 요구하여 반복적인 과정을 통해 쉽게 얻을 수 있다.→그래서 거대한 스케일 모델 사전 훈련에 쉽게 적용될 수 있다.
특히 (w,v)는 두 다른 분포$\mu,v$로 고려될 수 있는데$\mu=\Sigma^T_{i=1} a_i\delta_{w_i}$로 계산되고$v=\Sigma^K_{j=1}b_j\delta_{v_j}$로 계산된다.($\delta_{w_i}$는$w_i$의 중심에서 디랙 델타 함수이다.)
가중치 벡터$a=\{a_i\}^T_{i=1}\in \Delta_T$와$b=\{b_j\}^K_{j=1} \in \Delta_K$는 각각 T와 K차원의 심플렉스에 속한다.(즉$\Sigma^T_{i=1}a_i=\Sigma^T_{j=1}b_j=1$)
*이때 두 $\mu, v$는 확률 분포이다.
$\mu ,v$ 사이의 OT 거리(이는 (w,v) 쌍의 alignment loss와 같음)는 다음과 같이 정의된다.
$\displaystyle\mathcal{L}_{\text{WRA}}(\theta)=\mathcal{D}_{ot}({{\mu}},{{\nu}})=\min_{{\bf T}\in\Pi({\mathbf{a}},{\mathbf{b}})}\sum_{i=1}^{T}\sum_{j=1}^{K}{\bf T}_{ij}\cdot c({\mathbf{w}}_{i},{\mathbf{v}}_{j})\,,$
$\Pi({\mathbf{a}},{\mathbf{b}})=\{{\bf T}\in{\mathbb{R}}_{+}^{T\times K}|{\bf T}\mathbf{1}_{m}={\mathbf{a}},{\bf T}^{\top}\mathbf{1}_{n}={\mathbf{b}}\}$가 n차원의 전부 1인 벡터이고$c(w_i,v_j)$는 두$w_i, v_j$ 사이 거리를 평가하는 비용 함수이다.
실험에서는 코사인 거리$({\mathbf{w}}_{i},{\mathbf{v}}_{j})=1-\frac{{\mathbf{w}}_{i}^{\top}{\mathbf{v}}_{j}}{||{\mathbf{w}}_{i}||_{2}||{\mathbf{v}}_{j}||_{2}}$가 사용되었다.
행렬 T는 두 모달 사이의 alignment를 해석하는 전송 계획으로 표현되었다.
불행히도 T에 대한 정확한 최소화는 계산적으로 다루기 힘들고 저자는 OT 거리(디테일한 내용은 보완 파일에 있음)를 근사하기 위해 IPOT 알고리즘을 고려했다.

T를 풀고 난 후 OT 거리는 파라미터$\theta$를 업데이트하기 위해 사용될 수 있는 WRA 손실으로서 역할을 한다.
Masked Region Modeling(MRM)
MLM과 유사하게 이미지 지역을 샘플링하고 그들의 시각적 특징을 15%의 확률로 마스킹한다.
모델은 모든 단어 w와 남아있는 지역들을 바탕으로 마스킹된 지역을 복구하는 훈련을한다.
마스킹된 시각적 특징들은 0으로 대체된다.
텍스트 토큰들이 각기 다른 라벨로서 표현됨과 달리 시각적 특징들은 고차원이고 연속적이므로 class 우도함수를 통해 지도학습될 수 없다.
대신에 저자는 MRM을 위한 세 변수를 제안하는데 이는 같은 목적함수 base를 공유한다.
$\mathcal{L}_{\text{MRM}}(\theta)=\mathbb{E}_{(\mathbf{w},\mathbf{v})\sim D}f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{\setminus\mathbf{m}},\mathbf{w})\,.$ (4)
1) Masked Region Feature Regression(MRFR)
MRFR은 각 마스크된 지역vmv_m의 트랜스포머 아웃풋을 이것의 시각적 특징으로 회귀하는 것을 학습한다.
특히 FC layer를 통해 트랜스포머 아웃풋을 ROI pooled feature $r(v_m^{(i)})$와 같은 차원 벡터$h_\theta(v_m^{(i)})$로 전환한다.
그러고 둘 사이의 L2 회귀식을 적용한다:
$f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{\setminus\mathbf{m}},\mathbf{w})=\sum_{i=1}^{M}\|h_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)})-r(\mathbf{v}_{\mathbf{m}}^{(i)})\|_{2}^{2}$
2)Masked Region Classification(MRC)
MRC는 각 마스크된 지역에 대해 object semantic 클래스를 예측한다.
저자는 마스킹된 지역의 트랜스포머의 아웃풋를 FC layer로 넣어서 K object classes의 점수를 예측하는데 이는 추가적으로 소프트맥스 함수를 통해 normalize된 분포$g_\theta(v_m^{(i)})\in R^K$로 바뀐다.
주목할 점은 object categories가 제공되지 않는다면 정답 라벨이 없다는 것이다.
그러므로 저자는 Faster R-CNN으로부터 출력된 object detection을 사용하고 감지된 object category(가장 높은 신뢰점수를 가진)를 마스크된 지역의 라벨로서 사용하는데 이는 원 핫 벡터로 전환된다.$c(v^{(i)}_m)\in R^K$.
최종 목표함수는 cross=entropy(CE) 손실을 최소화하는 것이다.
$f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{\setminus\mathbf{m}},\mathbf{w})=\sum_{i=1}^{M}CE(c(\mathbf{v}_{\mathbf{m}}^{(i)}),g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)}))$
3)Masked Region Classification with KL-Divergence(MRC-kl)
MRC는 가장 있을법한 object class를 object detection model에서 하드 라벨(0또는 1만 존재)로 가져간다.
이때 감지된 object class는 해당 지역에 대한 정답 라벨이라고 가정한다.
하지만 정답 라벨이 존재하지 않을 경우 이는 사실이 아닐 수도 있다.
그러므로 MRC-kl에서 지도학습 신호로서 soft label을 사용에 의해 이 가정을 피하는데 이는 detector로부터의 raw output이다.(즉 object classes의 분포$c(v_m^{(i)})$.
MRC-kl는 두 분포 사이의 KL divergence를 최소화함으로써 이런 지식을 UNITER에게 증류(전달)해주는 것을 목표로 한다.
$f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{\setminus\mathbf{m}},\mathbf{w})=\sum_{i=1}^{M}D_{KL}(\tilde{c}(\mathbf{v}_{\mathbf{m}}^{(i)})||g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)}))$
3.3 Pre-training Datasets
사전 훈련에서 다양한 데이터 셋에 대한 다른 효과들을 공부하기 위해 네 개의 데이터 셋을 두 개의 카테고리로 나눴다.
In-domain: 대부분의 V+L 태스크가 훈련된 데이터 셋 카테고리

4. Experiments
UNITER를 사전 훈련된 모델로 가져와서 각 타겟 태스크에 대해서 미세 조정을 한 후 여섯 V+L 태스크에서 평가했다.
두 개의 모델이 있는데 12-layers의 UNITER-base와 24-layers의 UNITER=large이다.
4.1 Downstream Tasks
VQA와 VCR 그리고 NLVR에서 모델은 주어진 이미지와 텍스트 질문에 대해서 이미지 내용을 기반으로 정답을 예측했다.
Visual ENtailment에서 주어진 이미지가 의미론적으로 인풋 문장을 포함하는지 예측하는 것이다.
Classification 정확도는 세 클래스에 대해서 측정된다.(Entailment, Neutral, Contradiction)
Image-Text Retrieval에서 (COCO와 Flickr30K)을 사용하여 IR, TR을 평가
VQA,VCR,NLVR, Visual Entailment, Image-Text Retrieval에서 [CLS]토큰의 포현으로부터 image-text 쌍 인풋의 동시 임베딩을 출력했다.
Image-Text Retrieval에서 ranking 문제를 triplet 로스를 통해 긍정쌍과 부정쌍의 거리를 최대화하는 유사도 스코어를 계산하면서 정형화했다.
4.2 Evaluation on Pre-training Tasks
각 V+L 벤치마크들에서 다양한 사전 학습 세팅의 효율성을 평가
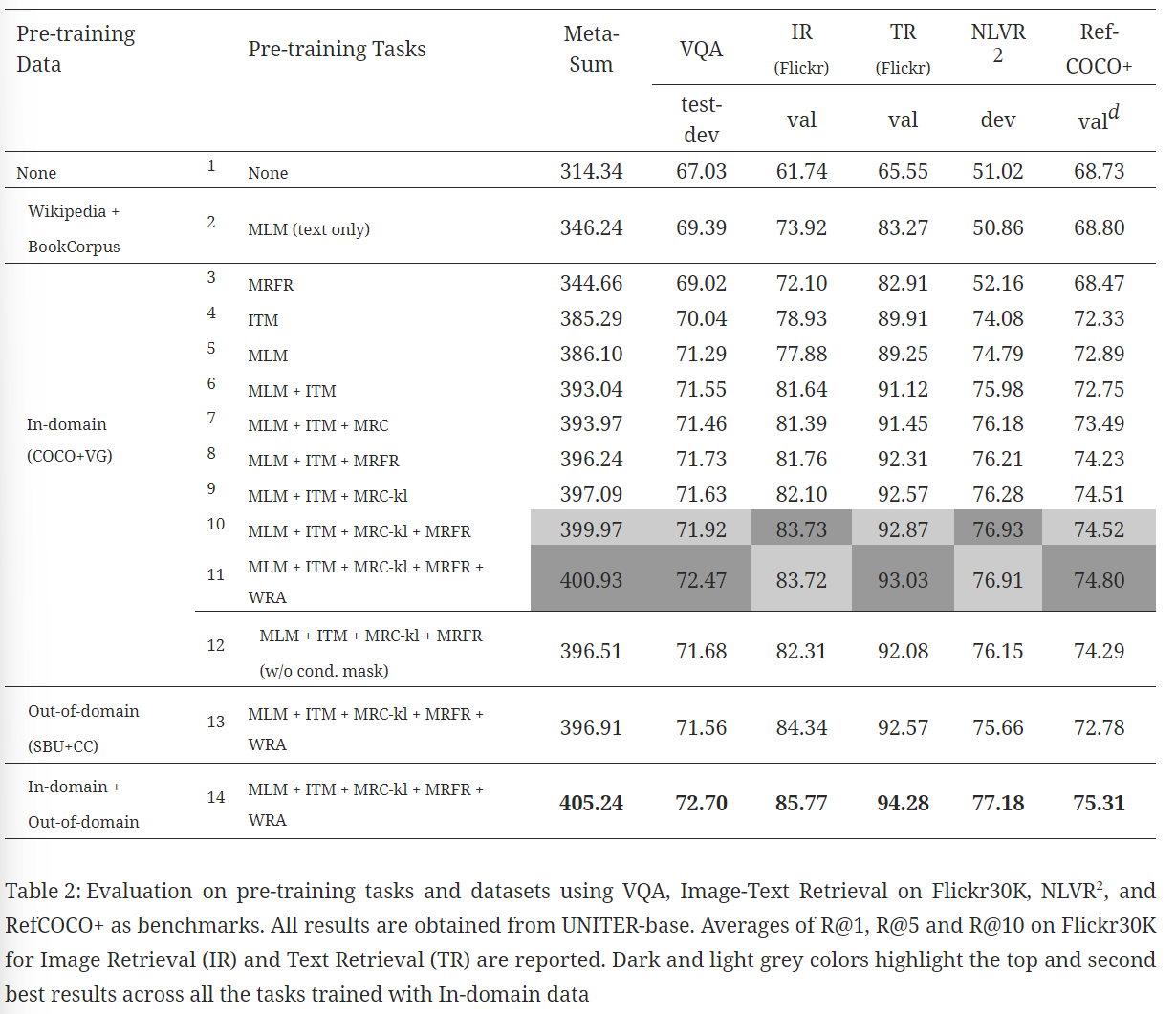
표준적인 평가지표에 추가하여 Meta-Sum(모든 벤치마크에 대한 점수의 합)을 global 평가 지표로 추가함
위 이미지에서 첫 번째 라인위는 아무런 사전 학습을 하지 않았고 두번째 라인은 다른 논문에서 사전 학습된 가중치를 가지고 MLM 초기화하여 나온 결과이다.
MLM이 텍스트에서만 훈련되었음에도, 사전 훈련동안 어떤 이미지 정보도 흡수하지 못함, Line 1보다 30점 높은 점수르 ㄹ보였다.
그러므로 이어지는 실험에서 모델을 초기화하기 위해 Line 2의 사전 훈련된 가중치를 사용했다.
이어서 각 사전 훈련 태스크의 효율성을 측정했는데 Line2 Line3를 비교하면 MRFR이 MLM보다 더 좋은 결과를 보였다.
반면 ITM 또는 MLM으로만 사전 훈련할 때 전 Line1, Line2보다 전반적으로 높은 성능 향상을 보였다.
다른 두 개의 사전 훈련 과제를 합쳤을 때
ML+ITM이 ITM 혹은 MLM 혼자보다 더 좋은 결과
MLM+ITM+MRM의 경우 L7-L10 모든 벤치마크에서 일정한 성능을 보임
MRM의 세 가지 변수 사이에서 MRC-kl이 MLM+ITM과 결합할 때 가장 좋은 성능을 보임을 확인 반대로 MRC는 가장 낮았음
MRC-kl과 MRFR을 MLM+ITM과 결합할 때(L10) 서로 보완적으로 작동하여 두 번째로 높은 Meta-Sum 점수를 받음
가장 높은 점수는 MLM+ITM+MRC-kl+MRFR+WRA이다(L11)
WRA를 추가하여 눈에 띄는 성능 향상을 관찰(특히 VQA와 RefCOCO+)
즉 이는 WRA를 통해 훈련된 단어와 지역간의 잘 훈련된 alignment는 region-level의 인지나 reasoning을 포함한 다운스트림 태스크에 좋은 영향을 준다는 점 발견
이어서 조건부 마스킹의 효과를 측정해봄
조건부 마스킹이 없을 때(L12) Meta-Sum의 감소
마지막으로 Out-of-domain에서의 성능 감소를 볼 때 사전 훈련과 유사한 다운스트림 태스크에 대해서 더 좋은 효과를 가져온다.
그런데 둘을 합쳐서 학습하면 성능 향상이 일어남
4.3 Results on Downstream Tasks
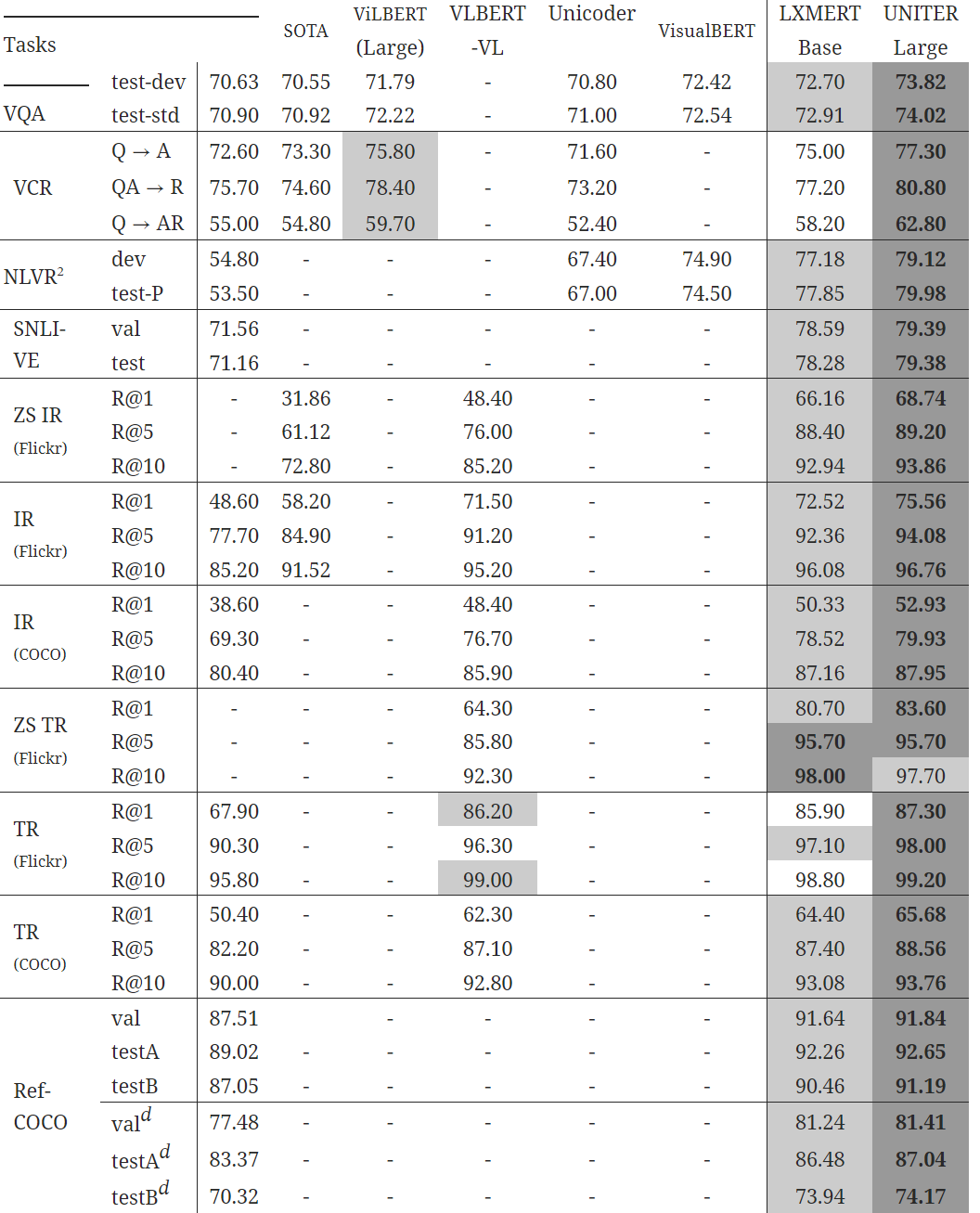
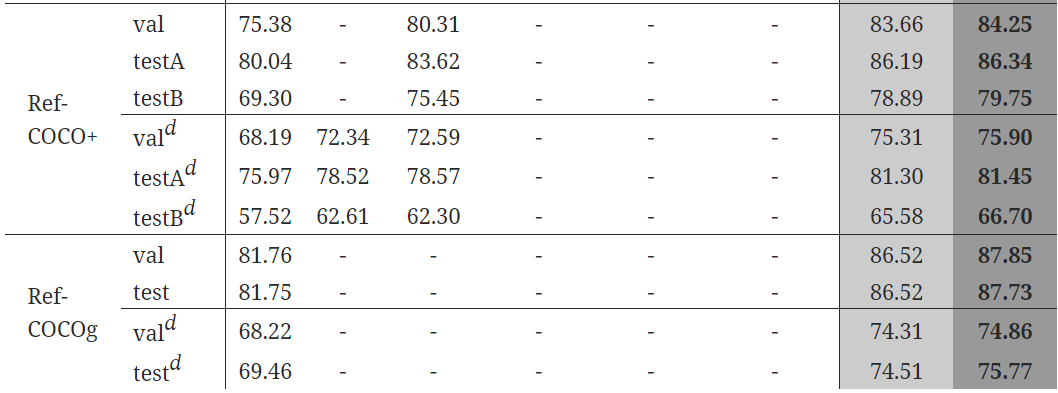
해당 base모델은 MLM+ITM_MRC-kl+MRFR+WRA이고 In-domain+Out-of-domain 데이터셋으로 훈련된 모델이다.